Blog
How OneTrust Helps Reduce Your Sensitive Data Footprint
Establish data retention and minimization policies to reduce your organization’s attack surface
January 15, 2026

The value of data today is greater than ever before, with companies looking for ways to optimize its collection and utilization to provide customers with timely, personalized experiences. As data’s value increases, so do the associated risks and costs. Cloud storage alone accounts for 30% of a company’s overall IT budget, with one terabyte (TB) of data costing $3,351 per year on average. That’s a cool $1M in storage costs alone for 300 TB of data. Apart from the rising costs of data storage, data breaches are also becoming more prevalent with the volume and variety collected by organizations today. he average damage of a data breach in 2025 sat at $4.4M.
The problem is clear. More data, more costs, more risk. More value? That’s up to how your organization makes use of it. Hoarding data or collecting it without a clear purpose not only increases the issues of storage cost and breach risk mentioned above, but also violates the GDPR, CPRA, and other major privacy regulations’ principles of data minimization and data retention policies.
Personal data shall be “adequate, relevant and limited to what is necessary in relation to the purposes for which they are processed”
– GDPR, Article 5(1)(c)
Unstructured Data and Its Challenges
Well, if it’s so clear that data minimization and data retention is the answer to high storage costs, data breach risks, and non-compliance issues, why isn’t everyone doing it? More than 80% of the data stored by organizations is unstructured.
This means it’s in the form of:
- Emails
- File attachments
- Images
- Pdfs
- Other forms of data which don’t have predefined fields like a structured database
This data also usually becomes meaningless in 90 days, and nearly a third of it is considered redundant, obsolete, and trivial (ROT). ROT data not only adds empty data storage costs, it’s also prime fodder for data breaches as it typically sits outside secure systems. It expands the attack surface of your company, which is all the possible risk areas from which an unauthorized user or attacker could breach your system.
Keeping these concerns with unstructured data and a growing attack surface in mind, most privacy regulations today call out the need to include data minimization practices as a part of standard operation procedures. Recent enforcement actions from the Federal Trade Commission (FTC) show that privacy and data security best practices have data minimization as a key tenet. Companies can start to include this in their data workflows, using privacy by design principles in their products or services to ensure data is minimized from the outset and collection and use are clearly communicated to customers.
How Can Companies Operationalize Data Retention and Minimization?
Now that the solution of incorporating privacy by design into your products and services from their inception is clear, the next step is figuring out how to integrate them into your processes seamlessly.
1. Observe your current data lifecycle
To kick things off, look at your most common data workflows and scenarios. Analyze your metadata to see relevant fields data created, last accessed/modified. Identify when data stops being necessary, where data is commonly deleted in these situations, and see how this could correlate to a data retention schedule.
2. Establish a deletion method
After identifying where data is deleted and formulating a retention schedule around these scenarios, you can apply these retention periods to your data, e.g. archiving or deleting SharePoint files after they cross a certain time threshold.
3. Use a centralized data governance tool
When your retention periods are defined and deletion methods are established, using a tool to power this mechanism is the most efficient way to go about this process.
- Determine the most accurate set of retention policies for your organization based on your relevant regulations
- Automate the retention and deletion process by setting business rules and applying them to your files
- Flag and identify any violations of retention rules in the system
- Decide whether data needs to be deleted, anonymized, or de-identified and carry out that action accordingly
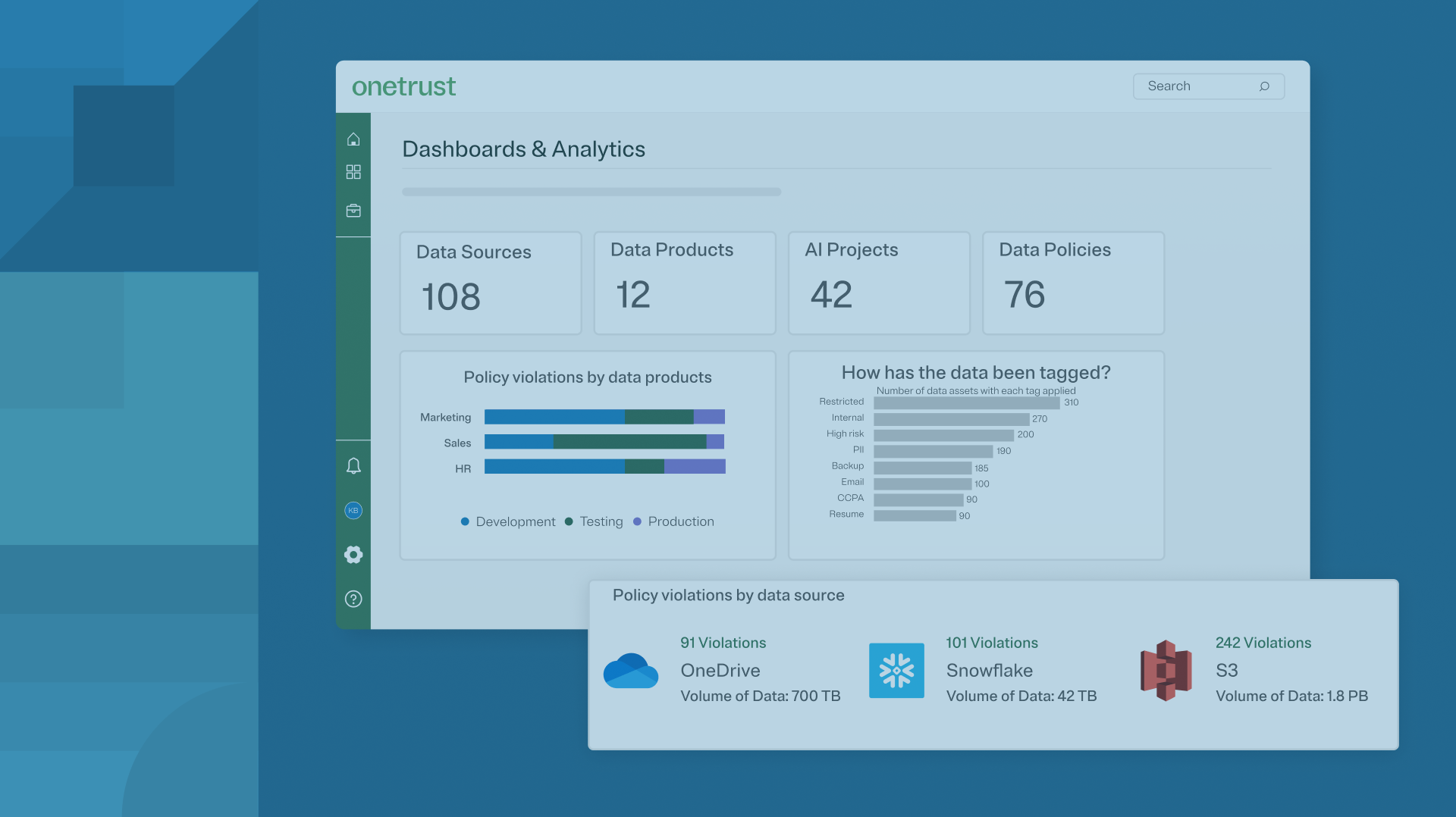
How OneTrust Helps Reduce Your Sensitive Data Footprint
OneTrust Data Use Governance enables organizations to operationalized data use with ongoing, automated programmatic enforcement rather than treating data governance as one-time cleanup exercise.
With unified visibility across structured and unstructured data, OneTrust enables teams to:
- Automatically classify data by sensitivity, context, and intended use.
- Discover and label data across cloud platforms, data stores, and collaboration tools, creating a trusted, AI-ready data foundation.
- Translate retention and minimization policies into enforceable controls.
- Orchestrate data policies across systems by embedding programmatic controls directly where data lives, ensuring consistent enforcement at scale.
- Continuously monitor data against governance standards
- Detect policy violations, over-sharing, and risky data use as environments evolve without relying on manual reviews or static reports.
- Demonstrate accountability with audit-ready insights
- Track policy adherence, surface trends, and identify at-risk data use with centralized analytics that support compliance, risk reduction, and operational efficiency.
By unifying data classification, policy orchestration, and continuous oversight, OneTrust enables organizations to reduce unnecessary data exposure, lower regulatory risk, and facilitate faster innovation with trusted data.
To see how OneTrust Data Use Governance helps you operationalize data governance at scale, request a demo today.
You May Also Like

Privacy Automation
Data Protection Leader Magazine | June 2026
Explore the June 2026 issue of Data Protection Leader, featuring analysis on the EU AI Act, China data minimization, India’s privacy law, and AI governance.
July 14, 2026

On-demand webinars
Responsible AI
Strengthening data governance to power responsible AI
Join our webinar to explore how data leaders are strengthening AI governance with trusted data foundations, quality management, and transparent practices.
August 05, 2025
On-demand webinars
Data Discovery & Security
Achieve AI-ready data with data policy enforcement
Discover how to modernize data governance for the AI era in this OneTrust webinar. Learn how to move from manual, static governance to dynamic, policy-centric enforcement with OneTrust Data Policy Enforcement.
June 18, 2025

On-demand webinars
Data Use Governance
The new data landscape: Navigating the shift to AI-ready data
This webinar will explore the how AI is affecting the data landscape, focusing on how data teams can extend common data practices to support AI’s unique use of data.
November 12, 2024

White Paper
AI Governance
How the EU AI Act and recent FTC enforcements for AI shape data governance
Download this white paper to learn how to adapt your data governance program, by defining AI-specific policies, monitoring data usage, and centralizing enforcement.
October 30, 2024

eBook
AI Governance
Data and AI governance for responsible use of data
Learn why discovering, classifying, and using data responsibly is the only way to ensure your AI is governed properly.
September 12, 2024

eBook
Privacy & Data Governance
Data governance across industries: Leveraging your organization's most valuable asset
Download our new eBook and learn how to leverage the value of data governance across industries, including financial services, healthcare, retail, and manufacturing.
April 17, 2024

Infographic
Data Discovery & Classification
Data governance in manufacturing: Challenges and use cases
Learn the impact a data governance program has in manufacturing and how it enables greater efficiency across your supply chain
February 26, 2024

Infographic
Data Discovery & Classification
What to look for in a data discovery solution
Make sure you choose the right data discovery solution for your organization with our comprehensive breakdown of key benefits and features to look for.
February 20, 2024
Infographic
Data Discovery & Classification
Data governance in retail: Challenges and use cases
Learn how data governance can help manage the high volume and sensitivity of data that runs through your retail operations.
February 12, 2024
Infographic
Data Discovery & Classification
Data governance in healthcare: Challenges and use cases
Learn how data governance can help your healthcare organization effectively manage its protected health information (PHI) and other sensitive data.
February 08, 2024

Infographic
Data Discovery & Classification
Data governance in financial services: Challenges and use cases
Learn how data governance can help address common challenges in the financial services industry and protect your most critical information.
January 12, 2024

On-demand webinars
Data Discovery & Security
A guided tour of OneTrust Data Discovery magic
Our expert speaker will demonstrate how common real-world data challenges can be identified, addressed, and reported on, leading to better data governance, security, and alignment with business goals.
October 26, 2023
On-demand webinars
Data Discovery & Security
Data minimization and risk assessment in data discovery
Explore the concept of data minimization and its crucial role in enhancing security, privacy, and reducing risk.
October 19, 2023
On-demand webinars
Data Discovery & Security
Data Discovery Dispelled: Data's dark corners
Join the first part of our Data Discovery Dispelled webinar series where we will discuss the hidden sensitive information that could pose risks for your organization.
October 12, 2023
Upcoming webinars
Data Discovery & Security
Data Discovery Dispelled: Unmasking the mysteries of data
Join us for a journey into the heart of data management as we explore the depths of data within organizations and shed light on how technology can enhance data security, privacy, and compliance.
October 12, 2023

Data Sheet
Data Discovery & Security
Data Discovery and Security
Explore our OneTrust Data Discovery and Security data sheet to learn how you can discover and control your data while enabling your teams.
September 18, 2023

eBook
Data Discovery & Classification
Ultimate guide to building a data governance program
Download this eBook and learn practical methods in building a flexible data governance program that aligns with your business.
August 13, 2023
On-demand webinars
Data Discovery & Classification
Live demo: OneTrust Data Discovery
See how OneTrust Data Discovery can help your organization achieve complete data visibility to empower your security program and reduce risk.
June 23, 2023
On-demand webinars
Data Discovery & Classification
Data responsibility: The information security professional’s higher purpose
Join OneTrust and KPMG for a dialogue with Information Security leaders on managing the balance between risk and reward when handling sensitive customer information.
June 20, 2023
On-demand webinars
Data Discovery & Classification
OneTrust Data Discovery Day: A deep dive into automating data discovery and classification
Join us for a two-hour deep dive into data discovery and how OneTrust helps privacy, IT, and security teams understaind their data and achieve risk reduction goals.
June 13, 2023
Infographic
Data Discovery & Classification
How OneTrust Data Discovery integrates with Microsoft 365
Explore three key integration capabilities of OneTrust Data Discovery and Microsoft 365.
June 13, 2023 3 min read
On-demand webinars
Trust Intelligence
How the Onetrust platform is innovating to unlock the value of trust
Join this webinar to learn how OneTrust is enhancing its privacy management, data governance, and consent and preferences solutions to help organizations tackle data sprawl and enable regulatory agility.
May 24, 2023
Data Sheet
Data Discovery & Security
Employee onboarding and offboarding management
Download our onboarding and offboarding management data sheet and learn how OneTrust Certification Automation can help reduce your risk exposure and improve compliance.
May 17, 2023

White Paper
AI Governance
Navigating responsible AI: A privacy professional's guide
Download our white paper and learn how privacy teams help organizations establish and implement policies that ensure AI applications are responsible and ethical.
May 03, 2023
Infographic
Data Discovery & Classification
The CISO challenge: Data. Threats. Regulations.
Unstructured data poses risks due to its open access and lack of governance, and CISOs need to implement measures to track, de-risk, and protect it.
March 03, 2023
On-demand webinars
Data Discovery & Security
Optimizing data usage through integrated data privacy and governance
Join us for a discussion on driving better business use and outcomes from data while ensuring regulatory requirements are met.
May 24, 2022
On-demand webinars
Data Discovery & Security
Rethinking trusted data
Join us for a discussion on the latest trends in trusted data and how you can take critical steps to build trust in data practices
May 24, 2022
On-demand webinars
Data Discovery & Security
Data Discovery South Africa: How to create value and demonstrate trust through your data?
Watch this webinar and discover how automated data discovery is helping clients in South Africa create value and demonstrate trust.
March 10, 2022
On-demand webinars
Data Discovery & Security
Data Discovery Türkiye: How to create value and demonstrate trust through your data?
Watch this webinar and discover how automated data discovery is helping clients in Türkiye create value and demonstrate trust.
March 09, 2022
On-demand webinars
Data Discovery & Security
Data Discovery Romania: How to create value and demonstrate trust through your data?
Watch this webinar and discover how automated data discovery is helping clients in Romania create value and demonstrate trust.
March 08, 2022
On-demand webinars
Data Discovery & Security
Data Discovery Hungary: How to create value and demonstrate trust through your data? | Resources | OneTrust
Watch this webinar and discover how automated data discovery is helping clients in Hungary create value and demonstrate trust.
March 08, 2022
On-demand webinars
Data Discovery & Security
Data Discovery Israel: How to create value and demonstrate trust through your data?
Watch this webinar and discover how automated data discovery is helping clients in Israel create value and demonstrate trust.
March 05, 2022
On-demand webinars
Data Discovery & Security
Privacy automation: bridging the gap between compliance & data governance to deliver trusted public services
Learn how you can take the first steps towards data intelligence and advance your privacy program to the next phase of automation and maturity.
January 18, 2022
On-demand webinars
Data Discovery & Security
Automating the classification and mapping of sensitive data
In this free webinar, learn how to automate the classification and mapping of sensitive data and speed compliance.
January 10, 2022
On-demand webinars
Data Discovery & Security
3 keys to a unified data governance program
Learn how properly governed data leads to better data quality, increased data intelligence and more trusted data.
August 27, 2021
On-demand webinars
Data Discovery & Security
Data intelligence: Using and improving your data
In the final webinar in the series, we explore the final step on the path towards data intelligence - using and improving your data.
July 19, 2021
Demo
AI Governance
OneTrust Data & AI Governance demo
Streamline data ingestion, ensure responsible AI, and enable secure data sharing with our Data & AI Governance solution. Empower teams to move to production faster while maintaining compliance and trust.