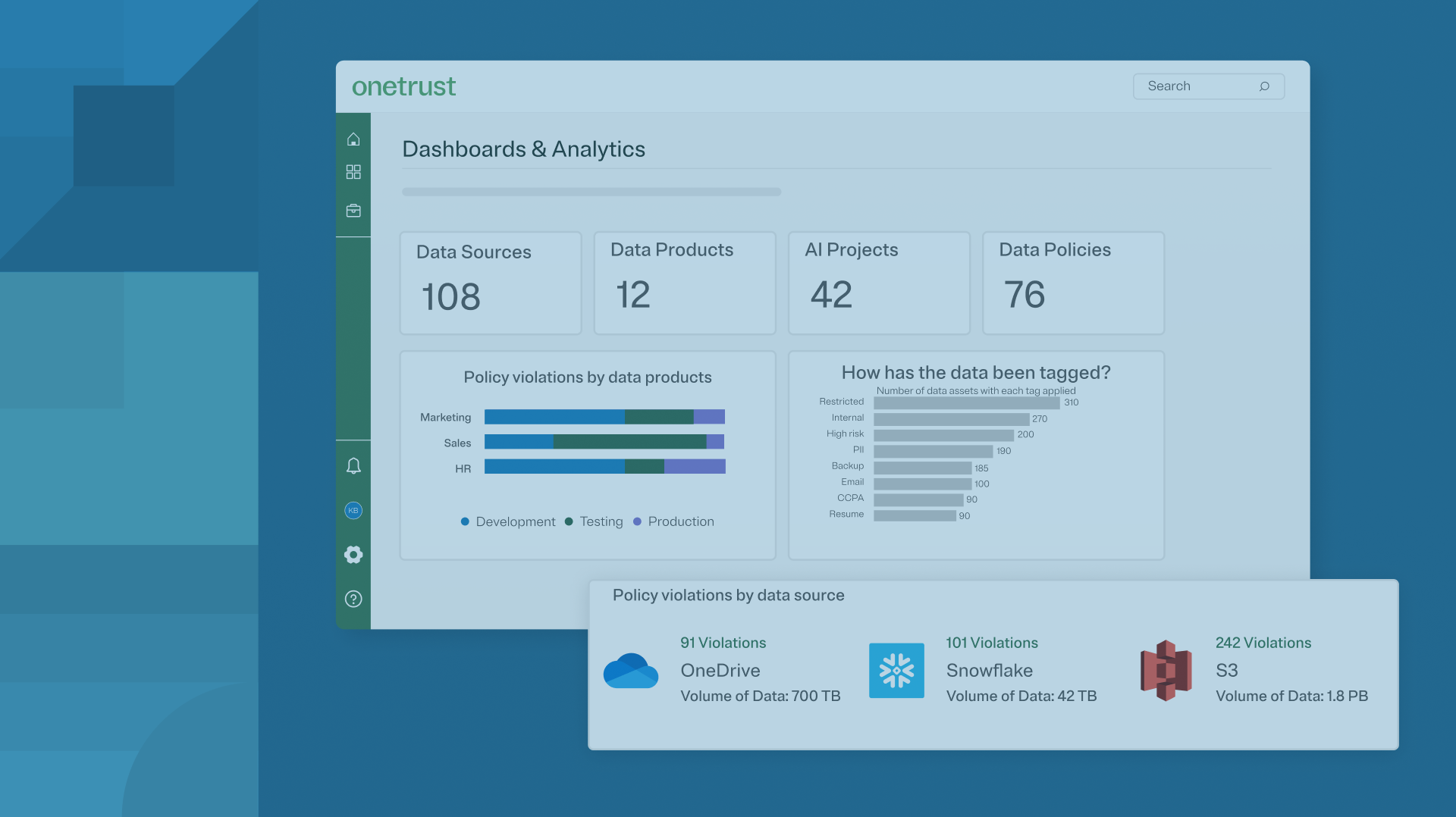
Data Governance continues to evolve. As organizations grow their data landscape, they turn to data governance to meet compliance requirements and derive greater value out of their data. This requires companies to move away from manual metadata management to an automated, smarter “data catalog.” Intelligent, automated data discovery for governance teams is essential to achieve data governance and data catalog objectives.
A data catalog enables various functions of an organization – such as marketing, sales, and even data science – to better source quality data needed to address business goals more readily. For an organization to truly have a comprehensive and well-populated data catalog representing their data, their data discovery needs to evolve beyond just metadata.
Metadata Only Scratches the Surface
It’s important to remember that you will never get a true understanding of your data when building a data catalog if you only look at the metadata level. Scanning a data asset or source just at the metadata level is essentially discovering the data at “face value.” The sheer volume and varieties of data that organizations must govern and a continually evolving data landscape often means that the actual data is very different from what the metadata states. This can be for several reasons:
- Human or machine errors often lead to incorrect or poor-quality data being found in data sources. These common errors range from simple ones such as surnames being held in a data column assigned to “first name” to completely incorrect information tables.
- Data drifts resulting in the mutations of data. When interactions take place with data over time, such as minor tweaks or major system upgrades, your data changes or drifts. Cloud migration is frequently a source of data drift. The changes caused by data drifts can impact your business’s processes in the long term and produce errors in predictive modeling.
While metadata discovery does offer some benefits, in most cases, it is insufficient for teams to understand what data you have, its categories, and types – a pillar of data governance. Governance teams must also utilize intelligent data discovery tools to go beyond metadata to understand their data better.
Understanding Unstructured Data Is Increasingly Important
Cataloging just metadata of unstructured data will give very little insight into that data. For this reason, traditional data governance programs would focus on structured data only. However, ignoring unstructured data is also missing a significant part of your data. To meet your compliance objectives and to uncover valuable data in all data sources, you need to scan and classify unstructured data.
Unstructured data must be accounted for to have a truly comprehensive governance program in place. This can only be achieved through a data discovery tool that scans and classifies unstructured data sources.
Request a demo: OneTrust DataDiscovery
Accurate Data Classification Relies on Scanning the Actual Data
Relying solely on metadata discovery does not allow proper classifications of data or a determination of the data’s sensitivity. For example, columns in databases will often contain a massive variance of data, resulting in great data sensitivity variations. Companies must be able to scan the actual data at the most granular, individual level. This allows governance teams to determine where their sensitive or restricted data is and eventually identify any that needs to be protected or have conditions placed on its use.
Additionally, GDPR, CCPA, and other privacy regulations have added additional privacy requirements and obligations to data management. Governance professionals must now include privacy considerations into their governance programs. Organizations must understand what PII they have for an individual and the categories of that data they have. This is accomplished through deep scanning of the data, which results in better compliance with privacy regulations by giving organizations the data intelligence they need to build a data map, uncover additional privacy risks, and fulfill privacy rights requests. Privacy awareness of your data that is critical for effective is data governance cannot be achieved simply by looking at your metadata.
OneTrust DataDiscovery provides governance teams with the power to find data assets, classify and enrich structured and unstructured data, classify and tag data to build a central data catalog and more. Businesses can easily establish ownership, responsibility, and stewardship of data to create powerful governance frameworks.