Unstructured data is any information that isn’t stored in a traditional row or column format and can be broadly defined. It is becoming a significant aspect of organizations’ data landscapes. In fact, up to 90% of the world’s data is held in an unstructured format. For most organizations, applications that store or process unstructured data such as Sharepoint, Outlook, Google Drive, and Slack are intrinsic to the day-to-day operations of the business. Just like all data, unstructured data has potential risks that need to be addressed by privacy, security, and governance professionals, however unstructured data poses unique risks that makes uncovering and addressing it particularly challenging.
Examples of Unstructured Data
- Text files or documents: Word processing documents, spreadsheets, presentations, document management systems, emails, and log files.
- Emails: Email is sometimes considered semi-structured data because the metadata in email is considered structured, since analytics tools can classify and search easily for keywords. However, the email message fields are unstructured because currently analytic tools cannot parse it.
- Media: Digital images, video, and audio files
- Social media: Data from social networks like Facebook, LinkedIn, and Twitter.
- Websites: Instagram, YouTube, and photo sharing sites are examples of unstructured data
Conversely, structured data is stored in a relational database or RDBMS so that it is identifiable, for example, a SQL (Structured Query Language). This type of data is easily mapped and organized into designated fields so that it can be searchable by data type within the actual content.
Watch the webinar: How to Uncover and Understand Unstructured Data
The Variety of Unstructured Data Sources Is Staggering – PNG, JPEG, TXT, PDF, CSV, MP4, Etc.
One of the biggest challenges of unstructured data is the huge variety in the data type. Access any file hosting or sharing application and you will likely find everything from PNGs and PDFs to TXT and MP4 files. The sheer range of file formats and quantities of data can be bewildering, yet they all contain data and therefore potentially personal or sensitive information. By the very nature of these file types, almost any information can be uncovered, which again, could be potentially incredibly sensitive data or categories of data that need to be protected or removed. Therefore, organizations are required to understand the types of data and classifications of data found in these files in order to meet data privacy and protection obligations. PDFs for example, can contain anything from bank account information, a complete profile of an individual, or huge lists of personal data. The same goes for images, which can easily contain classified information saved for use at a later date. Storing this type of unstructured data could mean a violation of internal privacy and security policies or, in the worst-case scenario, even the law.
Realistically, classifying and categorizing the data found within unstructured file types cannot be done manually due to the volume of data that would need to be processed. For a full and accurate picture of what is hidden in your unstructured data, automation is essential. Technology is a must for unstructured data discovery projects to find, comprehend, and catalog all of this data, allowing privacy, security, and governance teams the opportunity to implement the appropriate controls over it.
Accessibility: A Benefit Full of Unstructured Data Risk
A significant and beneficial feature of file hosting and sharing applications is the flexibility to allow users to host, share, and access files quickly and easily. Almost anything can be shared or accessed by almost anyone and for organizations, this promotes cross-functional collaboration, improves efficiencies for day-to-day tasks, and inspires innovation. Although with this flexibility comes a potential downside – data getting into the wrong hands. The aforementioned quantities of data and file types found in unstructured data and the potential for sensitive or restricted data to be contained in these files, combined with often open access to this data means that you are greatly increasing the likelihood of a major incident or breach involving restricted, personal or other protected data types. Understanding the classification of the data found in unstructured sources is rarely enough to govern this data properly. Once discovered, classified, and cataloged, proper access controls need to be applied to personal data and sensitive information and remedial action needs to be taken to understand who has, and who has had, access to better protect the data.
Have You Kept Your Data for Too Long?
Raise a hand if you have emails dating back years, or even decades stored on your email host’s server. Do you know what is contained in those emails? Now, extrapolate that email volume across hundreds or thousands of employees, and you can start to understand the scale of the problem that unstructured data causes for organizations. The personal information hidden within emails that have been lingering in the archives for years may now be in violation of data retention policies. And this problem extends further than just email, as files stored in file share applications can go unused and unaccounted for longer than is necessary and therefore need to be deleted. According to the GDPR, you have to justify the length of time you store data.
Watch the webinar: How to Uncover and Understand Unstructured Data
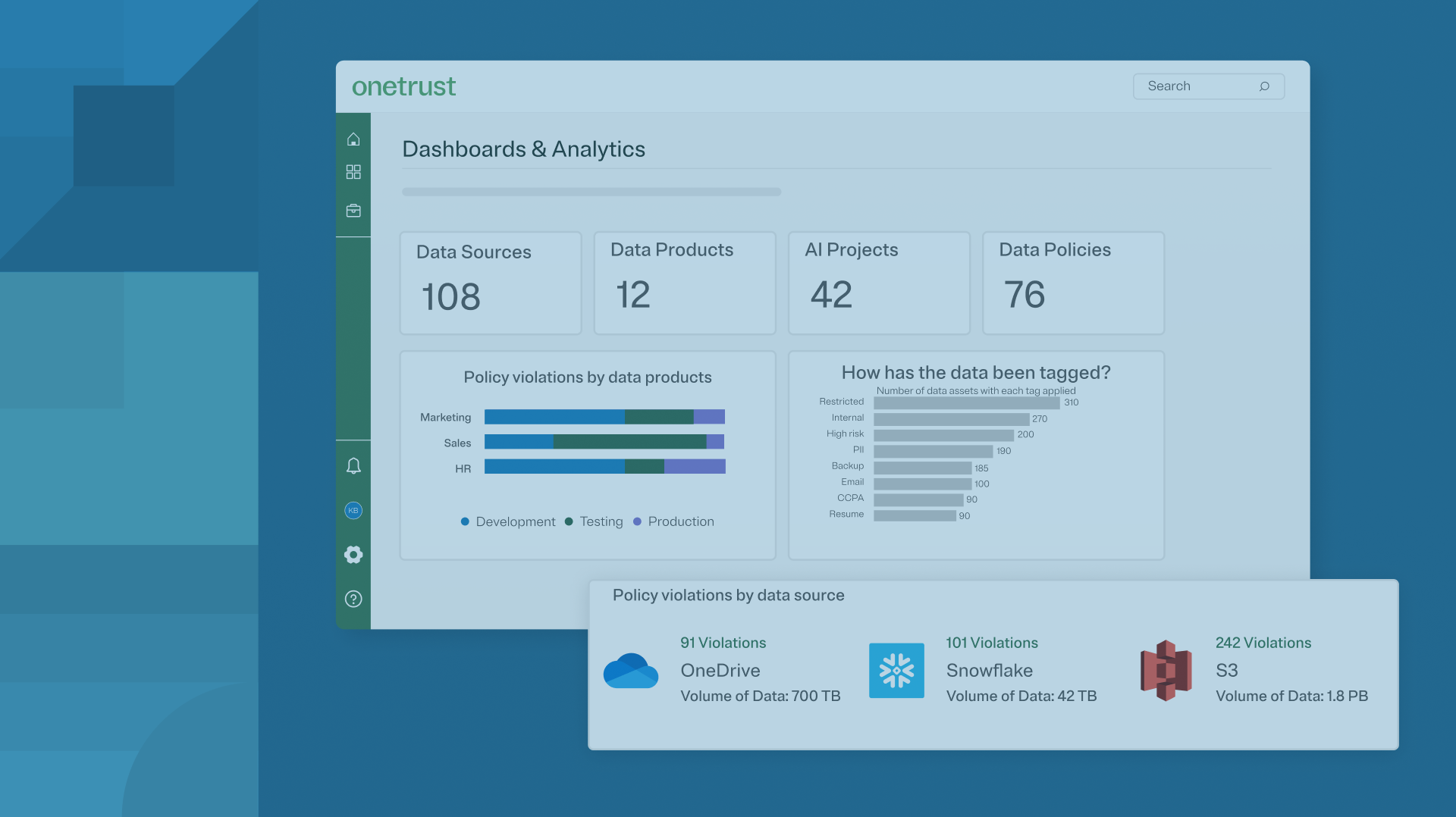
How OneTrust Data Discovery Helps
OneTrust DataDiscovery serves as a valuable tool for Chief Data Officers, Chief Privacy Officers, and Chief Information Security Officers alike. Enhanced unstructured data discovery capabilities help find unstructured data across common shared-use applications as well as understanding the compliance obligations attached to the sensitive or personal information found within these files. OneTrust’s enhanced unstructured data discovery capabilities utilizes advanced machine learning-based classification to give users a clearer view into at-risk, sensitive, or personal data down to the individual data element level and automatically populate data maps to help maintain compliance with privacy and security regulations. Moreover, OneTrust Data Discovery adds further context to your data by helping you understand who has access and that the right level of access is implemented alongside applicable governance policies. OneTrust Data Discovery automatically populates data inventories, giving governance teams a clear, centralized view of their data, helping with compliance obligations, retention periods, and access controls.
OneTrust’s enhanced unstructured data discovery capabilities integrate with the wider OneTrust platform of privacy, security, and governance solutions, helping organizations develop real data intelligence and utilizing unified architecture to add an additional layer of accuracy and understanding. Request a demo to learn more about OneTrust DataDiscovery’s enhanced unstructured data discovery capabilities or watch the webinar How to Uncover and Understand Unstructured Data.